Parallel Metropolis-Hastings
This post examines a particular method for parallelizing the Metropolis-Hastings algorithm.

In this post, I will discuss a generalization of the Metropolis-Hastings algorithm which is amenable to parallelization on multi-core CPUs or GPUs, etc.
Introduction
In computing, it is often necessary to draw random samples from some probability distribution. For instance, Metropolis light transport is a path-tracing rendering algorithm which samples light paths in a virtual scene according to their distribution of brightness in the rendered image.
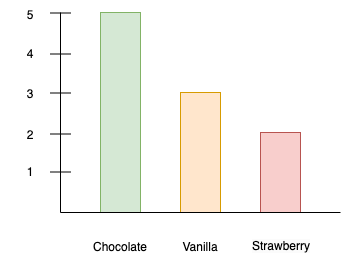
As a simple example, suppose that a group of people are surveyed regarding their favorite flavor of ice cream, as in Figure 1.
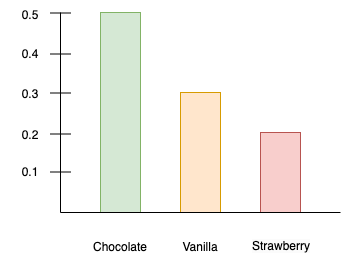
We can then compute a probability distribution (as a "probability mass function") by normalizing the histogram from Figure 1 by dividing each tally by the sum of all people surveyed (10), as in Figure 2.
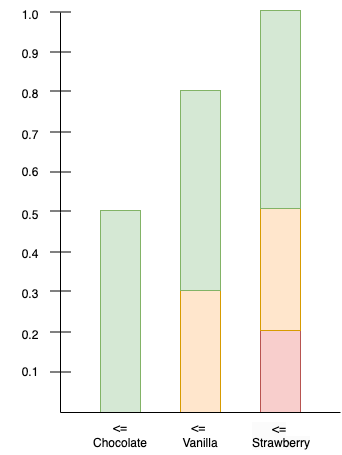
Suppose that we wish to draw random samples from this distribution. One method of doing so involves computing the inverse of the cumulative distribution. The cumulative distribution is depicted in Figure 3. If we impose an arbitrary total ordering on the flavors (e.g. chocolate is first, vanilla is second, strawberry is third, as depicted from left to right in the figure), then the cumulative distribution tells us the probability that a flavor is less than or equal to the respective flavor.
We can then compute the inverse of the cumulative distribution, which accepts a number
If we generate a random number
If the generated random numbers are uniformly distributed, then we will sample flavors proportionally, as is depicted in Figure 4.

There are other methods of sampling distributions, such as rejection sampling. In the case of discrete (finite) random variables, sampling a distribution is relatively straightforward. However, in general, sampling from a distribution is a difficult problem.
The Metropolis-Hastings algorithm is an ingenious technique for sampling a wide class of distributions: it constructs a Markov chain one step at a time, such that the stationary distribution of the chain is equal to the target distribution, and can do so only by evaluating a function which is proportional to the target distribution. At each step, the algorithm maintains the most recent sample and proposes a candidate sample and determines whether to accept or reject the given proposal based on a simple criterion.
However, as the term chain implies, the original algorithm can only generate samples sequentially, which is a serious problem when implementing the algorithm in a parallel manner, for instance on a GPU. The typical solution is to use multiple chains; however, this means that the chains are independent and "shorter" (consist of fewer steps, affording less opportunity to converge to the stationary distribution), and there is overhead, such as storage, associated with each chain, so using multiple chains can result in serious drawbacks.
However, there are generalizations of the Metropolis-Hastings algorithm which are amenable to parallelization and do not suffer any drawbacks. This post will discuss one particular such generalization which generates multiple independent proposals at each step (hence permitting the proposals to be generated in parallel), and then utilizes all proposals (not just the single accepted proposal, if any) by weighting them in an appropriate manner which preserves the stationary distribution and even reduces variance.
Papers
The algorithm which will be discussed in this post is described in the paper "Rao-Blackwellised parallel MCMC" [1] by authors Tobias Schwedes and Ben Calderhead (referred to as "RB-MP-MCMC" there). The earlier paper "A general construction for parallelizing Metropolis−Hastings algorithms" [2] by author Ben Calderhead also describes aspects of this algorithm. The algorithm is based on earlier work described in the paper "Using All Metropolis-Hastings Proposals to Estimate Mean Values" [3] by author Håkon Tjelmeland.
The original algorithm is described in the paper "Equation of State Calculations by Fast Computing Machines" [4] by Nicholas Metropolis which was extended in the paper "Monte Carlo Sampling Methods Using Markov Chains and Their Applications" [5] by W.K. Hastings (hence the name "Metropolis-Hastings").
See the references at the end of the post.
Before proceeding, a brief overview of probability theory is needed in order to establish the basic terminology and concepts.
Measures
Our goal is to assign a probability to certain sets (where we think of the sets as particular events). In order to do so, we must establish which sorts of sets are measurable.
A collection
The elements
Given two measurable spaces
Given a measurable space
- countable additivity:
The triple
A measure is called
Given any map
Probability Spaces
If
- A set
- A
- A probability measure
Thus, each event is a measurable set of outcomes, and the measure assigned to it is called its probability.
For instance, the sample space representing the outcome of the roll of a die could be represented by
Events are sets because sets represent arbitrary predicates (they are the extension of the predicate, i.e.
The conditional probability
Random Variables
Given a probability space
Random variables are functions, but they are often written in abbreviated notation. For instance, the probability that a random variable occupies a value in a measurable set
As another example, the probability that a random variable occupies a distinct value is often written as follows:
As another example, if the set
In general, for any appropriate predicate
The distribution (or probability distribution) of a random variable
A real-valued random variable is a random variable whose codomain is
The cumulative distribution function (CDF) of a real-valued random variable
The CDF completely characterizes the distribution of a real-valued random variable (i.e. each distribution has a unique CDF and conversely, each CDF corresponds to a unique distribution).
For random variables on discrete (finite or countable) measurable spaces, the probability mass function (PMF)
Each real-valued random variable generates a
Although probability spaces and random variables are important for theoretical purposes, the distribution of random variables is typically what matters, and so the probability space and random variables are suppressed (they are not defined explicitly). There might be many random variables defined on various probability spaces which exhibit the same distribution; it is the distribution itself that is important. There are theoretical results guaranteeing the existence of suitable probability spaces and random variables for a given distribution. Thus, generally, the distribution is used, typically via a CDF or PDF (see below).
Integrals
Given a real-valued measurable function
The same integral is sometimes denoted
or as
Consider Figure 5.
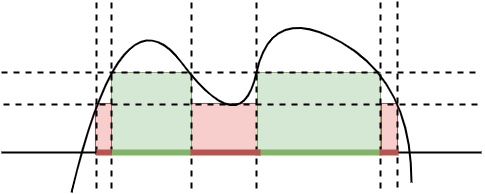
An indicator function
The integral of an indicator function is defined as follows:
A finite linear combination
where
If
Then, the integral of a non-negative measurable function
We can then define non-negative measurable functions as follows:
and
Then
and if
the function is said to be integrable.
Some details (such as assumptions regarding
Densities
The Radon-Nikodym Theorem is an important result in measure theory which states that, for any measurable space
The function
so that
A probability density function (PDF) of a random variable
and hence, for any measurable set
The distribution of a real-valued random variable admits a density function if and only if its CDF is absolutely continuous; in this case, the derivative of the CDF is a PDF:
Stochastic Processes
Given a probability space
The set
A stochastic process is stationary if each of its random variables have the same distribution.
Filtrations
Given a
such that
A stochastic process
Intuitively, a filtration models the information gathered from a stochastic process up to a particular point in the process.
Expectations
If
For each event
The conditional expectation of a real-valued random variable
- For each
The conditional probability of an event
Likewise, the conditional expectation of a real-valued random variable
Markov Processes
A stochastic process
This property is called the Markov property.
Intuitively, the Markov property indicates that a Markov process only depends on the most recent state, not on the entire history of prior states.
A Markov process is time-homogeneous if, for all
This property indicates that the transition probability is independent of time (i.e. is the same for all times).
A Markov process is called a discrete-time process if
Given measurable spaces
If a stochastic kernel is a probability measure for all
Markov Chains on Arbitrary State Spaces
A discrete-time, time-homogeneous Markov process consisting of real-valued (or real-vector-valued) random variables, for our purposes, will be called a Markov chain (although other types of Markov processes are also called Markov chains).
The initial distribution
We can then define a stochastic kernel
Since a Markov chain is time-homogeneous, this is well-defined.
The distribution
Likewise, the distribution
If the random variables admit densities, then
Likewise, the transition kernel can be expressed in terms of a conditional density
Then, each of the densities can be expressed as follows:
If the Markov process has a stationary distribution, that is, if each of the random variables has the same distribution
This equation is called the balance equation.
In terms of PDFs, the balance equation is expressed as
A Markov chain satisfies detailed balance if there exists a probability measure
Then, integrating both sides, we obtain
Thus,
and, since
it follows that
This is (with an appropriate change of variables) exactly the balance equation. Thus, detailed balance implies balance, i.e. it implies that
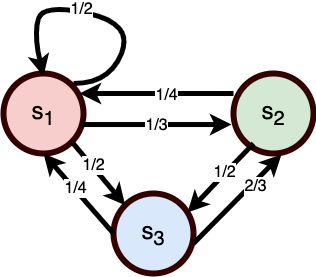
Example Markov Chain on a Finite State Space
It is instructive to consider an example of a Markov chain on a finite state space. We will work with the distributions, via the probability mass function (PMF) and cumulative distribution function (CDF).
Consider the following Markov chain:
- The state space
- The initial distribution
- The transition function
A Markov chain on a finite state space can be conceived as a state machine with probabilistic transitions, as in Figure 6.
Next, define the inverse CDF
We can then sample a state by generating a uniformly distributed random number
Then, we can define the next distribution
This uses the Law of Total Probability, i.e. the probability of occupying a given state
We can then define the next inverse CDF
We can then sample the next state by generating a uniformly distributed random number
This process can continue indefinitely. We can define the distribution
If the Markov chain possesses a stationary distribution, then it will be the limit as
Each distribution
Likewise, the transition function can be represented as a matrix
Then, each distribution
Expanding this recursive equation yields an iterative equation:
If the Markov chain possesses a stationary distribution
If we write
then this yields the equation
We must additionally impose the constraint that
Solving this yields
The Rao-Blackwell Theorem
The term parameter refers to a quantity that summarizes some detail of a statistical population, such as the mean, or standard deviation of the population, and is often denoted
The mean-squared error (MSE) of an estimator
The Rao-Blackwell estimator
One version of the Rao-Blackwell theorem states that the mean-squared error of the Rao-Blackwell estimator does not exceed that of the original estimator, namely
Another version states that the variance of the Rao-Blackwell estimator is less than or equal to the variance of the original estimator.
The Rao-Blackwell theorem can be applied to produce improved estimators. In particular, it will provide a means of using the rejected samples produced by the Metropolis-Hastings algorithm.
The Metropolis-Hastings Algorithm
The Metropolis-Hastings algorithm, like all MCMC techniques, designs a Markov chain such that the stationary distribution
A Markov chain is characterized by its transition probability
First, the condition of detailed balance is imposed, namely.
which guarantees the balance condition
Then, the transition distribution
The detailed balance condition then implies that
which further implies that
Often, the proposal distribution is designed to be symmetric, meaning that
and so this simplifies to
The typical choice for the acceptance distribution is
Then, either
Thus, the balance equation is also satisfied, and the stationary distribution of the chain will be the target distribution
Note that since the probability of acceptance is
Detailed balance guarantees the existence of a stationary distribution; the uniqueness of the stationary distribution is guaranteed under certain conditions (the ergodicity of the chain).
This yields a concrete algorithm:
- Choose an initial state
- Iterate:
- Generate a random proposal state
- Either accept the proposal or reject the proposal.
- Generate a uniformly distributed random number
- If
- If
- Generate a uniformly distributed random number
- Continue at time
- Generate a random proposal state
This algorithm will yield a sequence of states which represent samples from the target distribution.
Note that the proposal state is not used when it is rejected; it is possible to use it, however. We will return to this issue in the discussion of the Rao-Blackwell theorem.
A New Perspective on Metropolis-Hastings
A change in the perspective of the Metropolis-Hastings algorithm will indicate its potential generalization. The algorithm can be conceived in terms of an auxiliary Markov chain. The proposal state and the current state comprise the states of a two-state auxiliary Markov chain whose transition probabilities are given by the acceptance probabilities
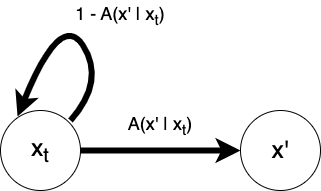
A new auxiliary chain is constructed during each iteration of the algorithm. The chain begins in state
We refer to the original Markov chain described explicitly in the Metropolis-Hastings algorithm as the primary chain to distinguish it from this implicit auxiliary chain.
This shift in perspective indicates several avenues toward generalization:
- A different auxiliary Markov chain can be constructed, in particular, one with multiple proposal states.
- The auxiliary Markov chain can be simulated for more than one step.
However, it is essential to ensure that the stationary distribution of the Markov chain is preserved.
In this post, we will not consider simulating the auxiliary chain for more than one step (but see references [1] and [2] for more information on this approach). This is less amenable to parallelization since it incurs significant coordination overhead. Instead, we will consider an auxiliary Markov chain with multiple proposal states which is simulated only once, yet each of the proposals is utilized via a Rao-Blackwell estimator. This approach allows the proposals to be computed in parallel, and minimizes the coordination needed.
Multiple Proposal Metropolis-Hastings
As in the single proposal case, we have a target distribution which is continuous on
Logically, we think of the process as follows: at each iteration of the Metropolis-Hastings algorithm, we produce an auxiliary Markov chain consisting of multiple proposal states, then we simulate the auxiliary chain for a single step to select the next state.
Just as in the single-proposal algorithm, we will maintain a single current state at each step of the process. However, we will propose an entire vector of proposals at each step.
We thus need to define the proposal density of a proposal vector given the current state.
First, denote the number of proposals as
We then use the notation
The notation
indicates the projection of
We can define a transition kernel
We can then define a multiple proposal density
Next, define a uniformly-distributed auxiliary random variable
Next, define a joint distribution as follows
Finally, denote the transition matrix of the auxiliary chain as
There will be a different transition matrix for each auxiliary chain, and each auxiliary chain corresponds to a different proposal vector.
We can now formulate the analog of the balance condition for the auxiliary chain:
Likewise, there is an analog of the detailed balance condition for the auxiliary chain:
In analogy to the single-proposal algorithm, the following transition matrix is used (which represents the acceptance distribution):
This transition matrix satisfies the balance equation. To see this, first denote the number of times
Preservation of Stationary Distribution
Now that we have defined the setting for multiple-proposal Markov chains, we need to establish several essential properties. First, the stationary distribution of the modified Markov process must be preserved, i.e. must still be equal to the target distribution
The following proof is adapted from appendix A of reference [1].
The notation
and
is used.
First, define a stochastic kernel as follows:
This kernel indicates the probability that the accepted sample
All transitions from the current state to the next have this form. Thus, we compute, for an arbitrary state
For any constant term
We may then re-associate the terms as follows:
Since the balance condition is satisfied, we then substitute as follows:
Then, just as before, since the sum does not affect the integral, we may eliminate it as follows:
Finally, we re-associate the terms and utilize the fact that
Thus, the transition kernel does indeed maintain the stationary distribution.
If we denote the distribution corresponding to the density
Noting that
it follows from the Radon-Nikodym theorem that
Likewise, by definition,
Thus, the balance equation is satisfied.
The Rao-Blackwell Estimator
MCMC techniques such as the Metropolis-Hastings algorithm are very often used to generate samples for use in numerical integration. When applying MCMC toward numerical integration, the sample mean
This is an unbiased estimator (that is,
This allows the calculation of arbitrary integrals by using
Our goal is to introduce an alternative estimator
We will begin with the sample mean estimator
and enhance it using the Rao-Blackwell estimator
We will proceed by using weighted samples weighted according to weights
We define the weights using the acceptance distribution as follows (given current index
The authors in [1] employ the following technique to derive the estimator. First, define the prefix sum of weights
This is related to the CDF of
Next, consider the following indicator function:
Note that, for any
In fact, this is an expression for the quantile (inverse CDF) function. This is why the sampling technique based on inverse CDFs works: it creates a random variable with the same distribution as another, yet with a different domain.
Thus, the expression is now reformulated on a convenient domain
Also note that
Since these uniformly distributed random numbers are independent of the proposed samples, the conditional expected value of the estimator with respect to the proposed samples is just the expected value of the estimator, namely
We then compute
Each iteration therefore produces the weighted estimate (the Rao-Blackwell estimator)
The estimator for the mean is thus
Unbiased Estimator
Next, we need to demonstrate that this new estimator is unbiased. The following proof is adapted from appendix A of reference [1].
We calculate the expected value with respect to the distribution
Then, splitting the sum into two terms, we continue to compute as follows:
Since the balance equation states that
and since
We may then infer that
Substituting this into the prior equation, we obtain
Noting that
we then substitute and obtain
Thus, this shows that
and that
The Final Algorithm
The parallel Metropolis-Hastings algorithm is as follows:
- Choose an initial sample
- Iterate:
- Generate
- Either accept a single proposal or reject all proposals (i.e. accept the current proposal):
- Generate a uniformly distributed random number
- If
- If
- Generate a uniformly distributed random number
- Incorporate the Rao-Blackwell estimator by weighting all proposed samples and the current sample according to
- Continue at time
- Generate
References
- Schwedes, T. & Calderhead, B. (2021). Rao-Blackwellised parallel MCMC . Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, in Proceedings of Machine Learning Research 130:3448-3456 Available from https://proceedings.mlr.press/v130/schwedes21a.html.
- B. Calderhead, A general construction for parallelizing Metropolis−Hastings algorithms, Proc. Natl. Acad. Sci. U.S.A. 111 (49) 17408-17413, https://doi.org/10.1073/pnas.1408184111 (2014).
- Tjelmeland H (2004) Using All Metropolis-Hastings Proposals to Estimate Mean Values (Norwegian University of Science and Technology, Trondheim, Norway), Tech Rep 4. Available from https://cds.cern.ch/record/848061/files/cer-002531395.pdf.
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. (1953). "Equation of State Calculations by Fast Computing Machines". Journal of Chemical Physics. 21 (6): 1087–1092. Bibcode:1953JChPh..21.1087M. doi:10.1063/1.1699114
- Hastings, W.K. (1970). "Monte Carlo Sampling Methods Using Markov Chains and Their Applications". Biometrika. 57 (1): 97–109. Bibcode:1970Bimka..57...97H. doi:10.1093/biomet/57.1.97. JSTOR 2334940